
模型参数
模型参数
模型参数是神经网络中通过训练调整的权重值,用于将输入数据映射到输出结果。在大模型中,参数规模通常以十亿(B)或万亿(T)为单位,例如GPT-3包含1750亿参数。参数决定了模型对输入数据的处理逻辑,如语言规则、图像特征提取等。
参数是模型的经验值,就像人经历越多越聪明,模型参数调整得越准,就能把输入和输出匹配得越好。参数多了,模型还能举一反三,比如从猫咪联想到喵星人。
为什么大模型参数重要
参数通过海量数据训练调整,使模型学会从输入到输出的映射规则。训练过程利用反向传播算法,根据预测误差逐步优化参数,最终让模型在翻译、问答等任务中表现更优。参数越多,模型能存储的知识越丰富,例如同时理解语法、语义和上下文。
模型参数怎么用
GPT-4通过千亿级参数实现了复杂语言任务(如写代码、创作故事),而谷歌PaLM则在翻译和多轮对话中表现优异。训练时,企业会分阶段优化参数:预训练(用全网数据打基础)、指令微调(教模型按指令执行)、对齐微调(确保输出符合人类价值观)。
总结
参数是什么:模型的脑细胞,数量越多越聪明,但算力需求也越大。
为什么重要:参数决定模型能学多深、记多细,像超级图书馆的书架越多,书就越全。
实际应用:从聊天机器人到自动驾驶,参数让AI更贴近人类思维,但需平衡智商与成本。
参数是大模型的智慧颗粒,堆得多能成天才,但也要避免变成书呆子(过拟合)或吃电怪兽(高能耗)。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 提拉的Studio!
相关推荐

2025-07-18
Agent
AgentAgent是一种基于大型语言模型的智能体,能够通过自主感知、规划、决策和执行完成复杂任务。它具备环境交互能力,可调用工具、记录历史信息,并根据目标拆解问题步骤,最终输出解决方案。 Agent就像一个全能助手,不仅可以回答问题,还能主动帮你完成任务,会做事。 Agent原理Agent的核心架构包括大语言模型(理解意图)、记忆模块(记录长期经验与短期上下文)、规划模块(拆解目标为子任务)和工具调用模块(执行如搜索API、写代码等操作)。通过模仿人类“目标-反思-行动”的思维链,实现任务闭环。 Agent实践案例会议助手:自动预定会议、发送通知、总结纪要,还能跨平台搜索并整理资料。个人助手:如“扣子”平台,用户可通过拖拽工具模块(日历、支付等)自定义Agent,实现自动记账、会议提醒等功能。智能客服:用户提问时,Agent先检索知识库,再调用订单查询接口,最终用自然语言生成回复,并记录问题到“长期记忆”以优化后续服务。 总结大模型Agent是能独立完成复杂任务的智能体,技术核心在于模拟人类思维链,结合记忆、规划和工具调用。当前已应用于客服、办公等场景,未来可能成为AI领域的“...

2025-07-18
LoRA
LoRA Low-rank adaptationLoRA(低秩自适应)是一种参数高效微调(PEFT)方法。其核心思想是通过低秩矩阵分解模拟大模型参数的增量更新:冻结预训练模型权重,仅在原始权重旁注入可训练的秩分解矩阵(一对小型线性投影矩阵),通过矩阵乘法实现参数调整。该方法显著减少需优化的参数量(通常降至原模型的0.1%),同时保持原始模型结构不变。 graph LR A[加载预训练模型] --> B[冻结所有权重] B --> C[识别关键层插入LoRA模块] C --> D[仅训练LoRA矩阵A/B] D --> E[保存LoRA权重文件] E --> F[实时加载适配器预测] LoRA原理核心原理:冻结权重+低秩分解 LoRA的革新性在于以下核心技术: 1.冻结原始模型 保持预训练模型的所有权重固定不变 避免对原始知识造成干扰 2.创建低秩适应矩阵12345678910111213141516171819202122232425262728293031323334353637383940414...

2025-07-18
MCP
MCP Model Context ProtocolMCP(模型上下文协议)是由Anthropic于2024年11月提出的开放协议,旨在为大语言模型与外部数据源、工具之间建立标准化接口。它采用客户端-服务器架构,定义统一的通信规范,使大模型能动态调用实时数据(如数据库、API)和功能(如绘图、文件操作),打破模型训练的信息孤岛。 MCP就像一个万能插座,让大模型能即插即用地连接各种工具和数据。比如,原本大模型不知道今天天气,但通过MCP协议,它能调用天气预报接口,像人一样实时查数据回答问题。 MCP原理MCP Host(主机环境):集成大模型的应用程序(如VSCode Copilot,Dify,Coze),负责执行AI任务并运行MCP客户端。MCP Client(客户端):作为中介模块(如Cursor),在主机环境中管理通信,向服务器查询可用工具列表、转发调用请求,并处理响应。MCP server(服务器端):封装外部工具接口(如数据库、API)。 MCP就像工厂流水线,主机运行AI大脑干活,客户端负责传话找工具,服务器存着数据库等外挂设备,客户端把需求告诉服务器,拿到结果再传回...

2025-07-18
Prompt
PromptPrompt(提示词)是用户与大语言模型交互时输入的指令或文本片段,用于引导模型生成符合预期的内容。它可以是问题、任务描述,或包含背景、示例的结构化文本,本质上是人与模型沟通的桥梁。 为什么Prompt重要Prompt工程的核心意义在于解决大模型的模糊性。模型虽然拥有海量知识,但无法直接理解人类意图,它不会通过一个眼神读懂你,你需要清晰告诉它你需要具体的什么,希望它怎么做。通过设计优质prompt,可以明确任务边界、提供上下文,从而缩小模型的想象空间,提升输出的相关性和准确性。 怎么写出优质提示词明确任务:用动词开头(如“总结”、“对比”等),指定输出角色(如“你是一名律师”)提供上下文:补充背景信息(如“用户是新手妈妈”)和示例结构化格式:要求分点、表格或JSON输出优化策略:使用RTF框架(角色-任务-格式)、思维链(“请逐步分析”,“请给出详细步骤”) 告诉大模型要干嘛,然后补充一些背景资料让它知道,最后规定答案格式,告诉它你要的是什么。 总结Prompt是与大模型高效沟通的密码。通过明确指令、补充细节和规范格式,将模糊需求转化为机器可执行的任务。
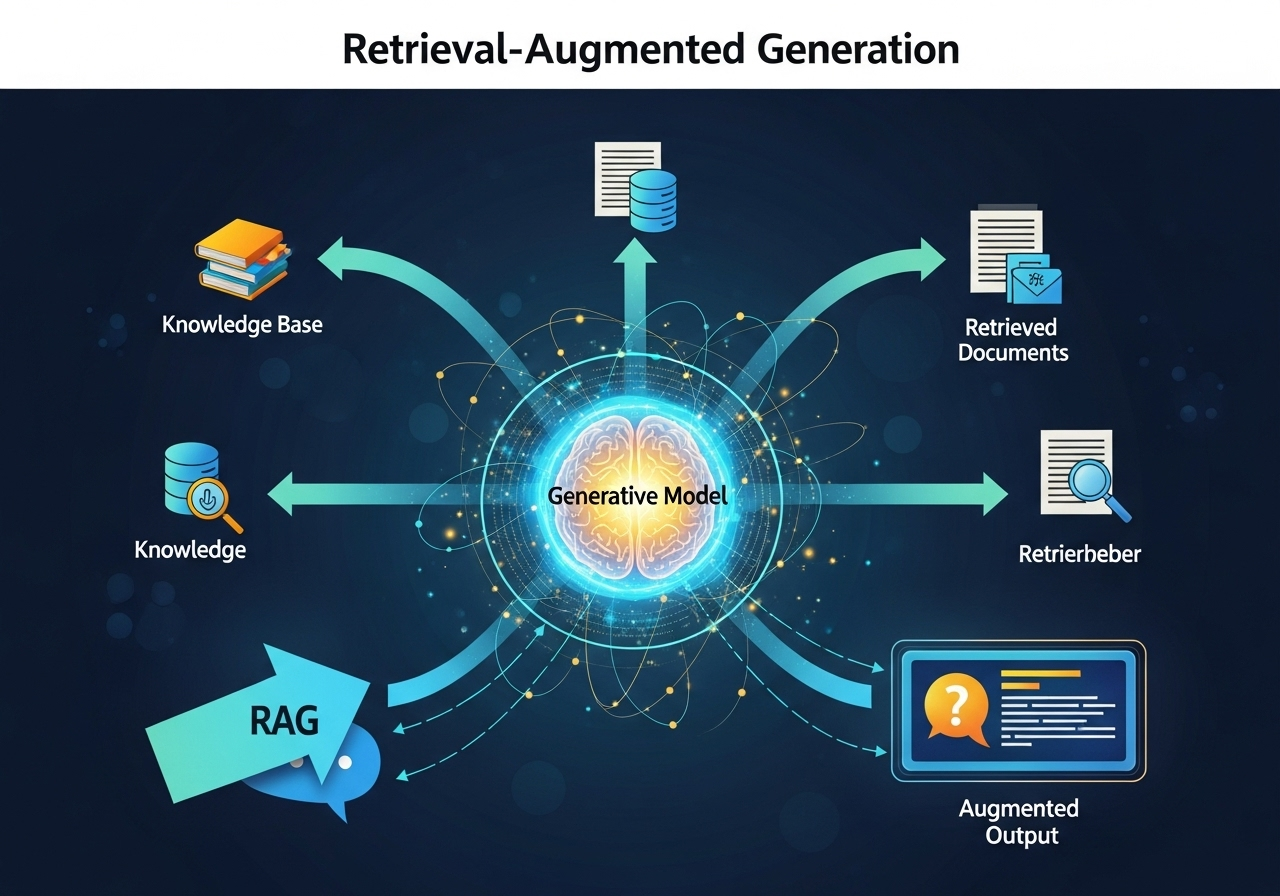
2025-07-18
RAG
RAG Retrieval-Augmented GenerationRAG检索增强生成是一种结合信息检索与大语言模型的技术框架。核心是通过外部知识库动态检索相关信息,将其与用户问题结合,增强模型生成答案的准确性和专业性。RAG无需修改模型参数,而是以外挂方式扩展LLM的知识边界,尤其适用于知识密集型任务(如问答、文档分析)。 RAG相当于给大模型外接了一个移动硬盘。当大模型遇到不确定的问题时,会先从这个硬盘里面快速搜索相关知识点,再结合自己本身的记忆给出更靠谱的答案,避免瞎编或过时信息的问题。 RAG原理数据准备:将文档拆解、编码为向量存入数据库。检索增强:将用户问题编码后匹配相似向量片段。生成优化:将检索结果与大模型能力结合,通过提示模版生成最终答案。 RAG怎么用ChatPDF:用户上传PDF后,RAG自动解析文本、建立索引(OpenAI,Cohere等模型的Embeddings API允许用户传入自己的文本数据进行向量化处理),回答时检索相关内容生成总结,适合学术文献分析。金融领域:银行用RAG构建智能客服,检索内部政策文档和产品手册,生成合规且专业的回复,避免信息泄露风险...

2025-07-18
Token
TokenToken是大语言模型处理文本的最小语义单元,通过分词算法将原始文本切割为可计算的离散符号。不同于传统的汉字或单词,它采用BPE等算法实现跨语言混合拆分,每个token对应词表中的唯一ID并转换为高维向量。 Token就像是组成物质的基础颗粒,它有自己的编号和数字坐标,编号是它的唯一id,而数字坐标由embedding得来,是一个高维向量,由输入的数据集得来。 为什么Token重要Token是模型资源消耗的计算单位,直接影响API调用成本(如GPT-4每千token约0.3元)、上下文记忆长度(如4096 tokens限制)和生成质量。合理的token使用能优化算力分配,避免关键信息被截断。 这其实是影响和大模型对话的三大体验:要花多少钱、能聊多长、回答质量。 怎么减少Token输入优化:删除冗余词 (“那个…嗯”,重复语义的)参数控制:设置max_tokens = 300限制回答长度长文本处理:分段输入+用“继续”指令衔接监控用量:调用API时查看usage字段 总结Token是AI理解人类语言的乐高积木,既决定了大模型的算力成本,又影响着对话质量。掌握分词...

