
Deepseek使用与Prompt工程
Deepseek使用与Prompt工程
AI大模型(如GPT、LLaMA、Claude等)的核心原理及API使用涉及多个技术层面。以下从基本原理、关键技术和实践API调用三个维度展开说明:
AI大模型基本原理
- 核心架构(以GPT为例)
graph TD
A[输入文本] --> B[Token化]
B --> C[嵌入层:转换为768/12288维向量]
C --> D[多层Transformer解码器]
D --> E[输出概率分布]
E --> F[采样生成文本]
Transformer结构:基于自注意力机制(Self-Attention),每个token可并行处理
训练目标:通过海量文本的“下一个词预测”任务(如Google的BERT采用MLM不同)
以上架构是用来不断生成下一个词,但是往往是顺着prompt说话的捧哏的角色,回答往往差强人意。大模型之所以能够给出优秀的令人满意的回答,训练过程离不开reward model。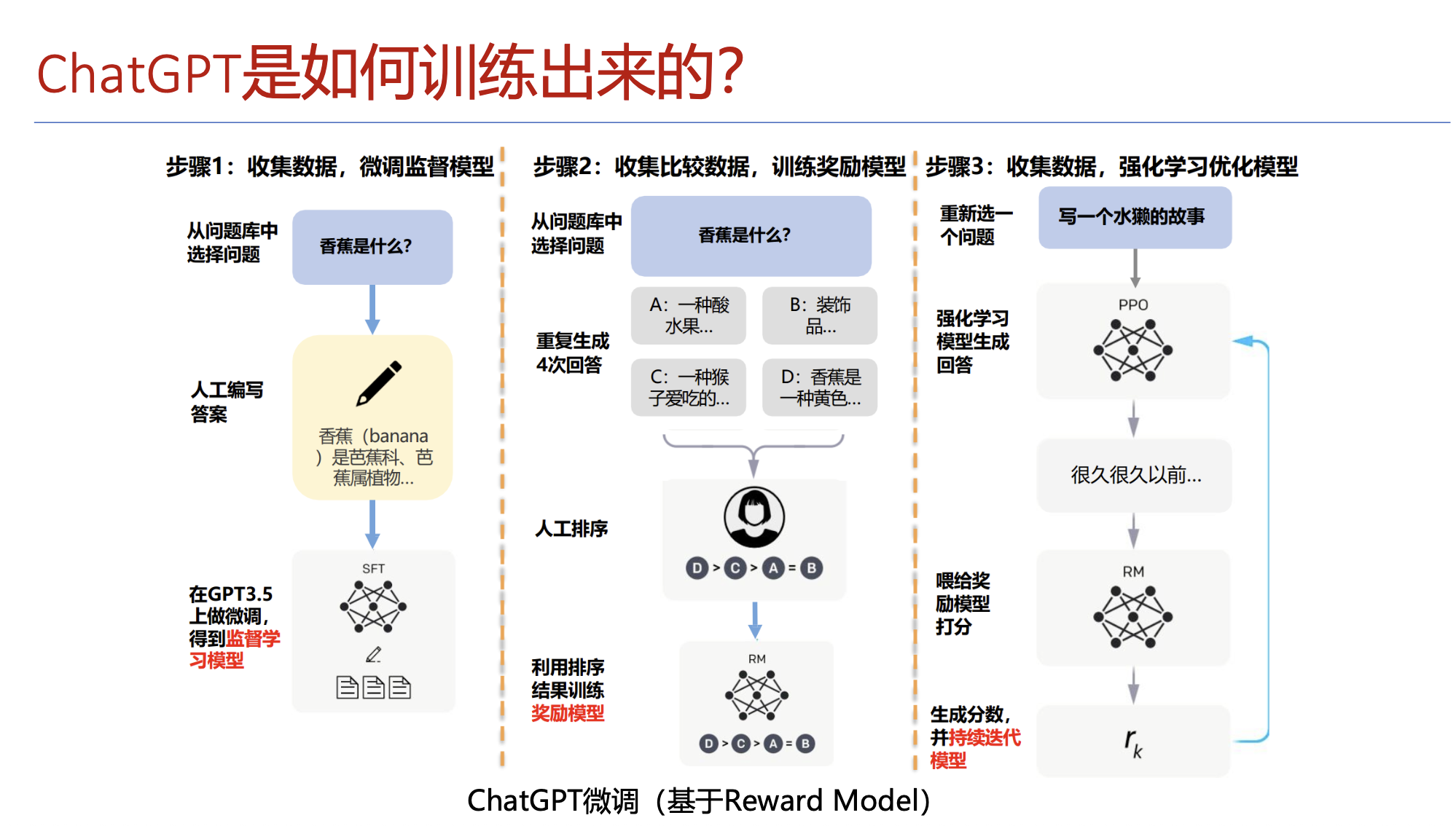
关键技术指标
参数 GPT-3 LLaMA-2-70B Claude-3 参数量 1750亿 700亿 未公开 训练数据量 3000亿token 2万亿token 超5万亿token 上下文窗口 2048token 4096token 200Ktoken 推理过程特殊设计
温度参数(Temperature):控制生成随机性(0.1=保守,1.0=创意)
Top-p采样:仅从概率累积超过p阈值的候选词中选取(如p=0.9)
停止标记:预设<|endoftext|>等标记终止生成
主流大模型API使用指南
- OpenAI API(GPT系列)
1 | import openai |
关键参数说明:
frequency_penalty(-2.02.0):抑制重复用词2.0):鼓励提及新概念
presence_penalty(-2.0
logit_bias:手动调整特定token概率
- Anthropic Claude API
1 | from anthropic import Anthropic |
差异化功能:
支持10万+长上下文记忆
内置XML标记解析能力
- 本地部署方案(LLaMA2为例)
1 | # 使用HuggingFace Transformers |
API调优实践技巧
- 提示工程(Prompt Engineering)
思维链(Chain-of-Thought):
用户:计算(125 + 378) × 4
系统:请逐步思考:- 先计算括号内:125+378=503
- 再乘以4:503×4=2012
最终答案:2012
少样本学习(Few-shot):
1 | messages=[ |
成本控制方案
策略 效果 适用场景 流式传输(stream=True) 减少响应延迟 长文本生成 限制max_tokens 直接控制费用 精准问答场景 缓存机制 避免重复请求 高频相似查询 异常处理建议
1 | try: |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 提拉的Studio!
相关推荐

2025-07-18
AI大模型基本原理及API使用
AI大模型基本原理及API使用AI大模型(如GPT、LLaMA、Claude等)的核心原理及API使用涉及多个技术层面。以下从基本原理、关键技术和实践API调用三个维度展开说明: AI大模型基本原理 核心架构(以GPT为例) graph TD A[输入文本] --> B[Token化] B --> C[嵌入层:转换为768/12288维向量] C --> D[多层Transformer解码器] D --> E[输出概率分布] E --> F[采样生成文本] Transformer结构:基于自注意力机制(Self-Attention),每个token可并行处理训练目标:通过海量文本的“下一个词预测”任务(如Google的BERT采用MLM不同) 以上架构是用来不断生成下一个词,但是往往是顺着prompt说话的捧哏的角色,回答往往差强人意。大模型之所以能够给出优秀的令人满意的回答,训练过程离不开reward model。 关键技术指标 参数 GPT-3 LLaMA-2-70B C...

2025-07-18
Agent
AgentAgent是一种基于大型语言模型的智能体,能够通过自主感知、规划、决策和执行完成复杂任务。它具备环境交互能力,可调用工具、记录历史信息,并根据目标拆解问题步骤,最终输出解决方案。 Agent就像一个全能助手,不仅可以回答问题,还能主动帮你完成任务,会做事。 Agent原理Agent的核心架构包括大语言模型(理解意图)、记忆模块(记录长期经验与短期上下文)、规划模块(拆解目标为子任务)和工具调用模块(执行如搜索API、写代码等操作)。通过模仿人类“目标-反思-行动”的思维链,实现任务闭环。 Agent实践案例会议助手:自动预定会议、发送通知、总结纪要,还能跨平台搜索并整理资料。个人助手:如“扣子”平台,用户可通过拖拽工具模块(日历、支付等)自定义Agent,实现自动记账、会议提醒等功能。智能客服:用户提问时,Agent先检索知识库,再调用订单查询接口,最终用自然语言生成回复,并记录问题到“长期记忆”以优化后续服务。 总结大模型Agent是能独立完成复杂任务的智能体,技术核心在于模拟人类思维链,结合记忆、规划和工具调用。当前已应用于客服、办公等场景,未来可能成为AI领域的“...
2025-07-18
Embedding与向量数据库
From Large Language Models to Reasoning Language Models - Three Eras in The Age of Computation. Era of model size scaling 模型规模扩展的时代2017 - Transformers “Attention is All you Need” 核心思想与贡献 目标:用纯注意力机制(无需RNN/CNN)解决序列建模问题,实现并行化训练并捕获长距离依赖。 关键创新: **自注意力(Self-Attention)**:动态计算序列中所有位置间的关联权重。 **多头注意力(Multi-Head Attention)**:并行学习不同子空间的注意力模式。 **位置编码(Positional Encoding)**:注入序列顺序信息,替代RNN的时序性。

2025-07-18
LoRA
LoRA Low-rank adaptationLoRA(低秩自适应)是一种参数高效微调(PEFT)方法。其核心思想是通过低秩矩阵分解模拟大模型参数的增量更新:冻结预训练模型权重,仅在原始权重旁注入可训练的秩分解矩阵(一对小型线性投影矩阵),通过矩阵乘法实现参数调整。该方法显著减少需优化的参数量(通常降至原模型的0.1%),同时保持原始模型结构不变。 graph LR A[加载预训练模型] --> B[冻结所有权重] B --> C[识别关键层插入LoRA模块] C --> D[仅训练LoRA矩阵A/B] D --> E[保存LoRA权重文件] E --> F[实时加载适配器预测] LoRA原理核心原理:冻结权重+低秩分解 LoRA的革新性在于以下核心技术: 1.冻结原始模型 保持预训练模型的所有权重固定不变 避免对原始知识造成干扰 2.创建低秩适应矩阵12345678910111213141516171819202122232425262728293031323334353637383940414...

2025-07-18
MCP
MCP Model Context ProtocolMCP(模型上下文协议)是由Anthropic于2024年11月提出的开放协议,旨在为大语言模型与外部数据源、工具之间建立标准化接口。它采用客户端-服务器架构,定义统一的通信规范,使大模型能动态调用实时数据(如数据库、API)和功能(如绘图、文件操作),打破模型训练的信息孤岛。 MCP就像一个万能插座,让大模型能即插即用地连接各种工具和数据。比如,原本大模型不知道今天天气,但通过MCP协议,它能调用天气预报接口,像人一样实时查数据回答问题。 MCP原理MCP Host(主机环境):集成大模型的应用程序(如VSCode Copilot,Dify,Coze),负责执行AI任务并运行MCP客户端。MCP Client(客户端):作为中介模块(如Cursor),在主机环境中管理通信,向服务器查询可用工具列表、转发调用请求,并处理响应。MCP server(服务器端):封装外部工具接口(如数据库、API)。 MCP就像工厂流水线,主机运行AI大脑干活,客户端负责传话找工具,服务器存着数据库等外挂设备,客户端把需求告诉服务器,拿到结果再传回...

2025-07-18
Prompt
PromptPrompt(提示词)是用户与大语言模型交互时输入的指令或文本片段,用于引导模型生成符合预期的内容。它可以是问题、任务描述,或包含背景、示例的结构化文本,本质上是人与模型沟通的桥梁。 为什么Prompt重要Prompt工程的核心意义在于解决大模型的模糊性。模型虽然拥有海量知识,但无法直接理解人类意图,它不会通过一个眼神读懂你,你需要清晰告诉它你需要具体的什么,希望它怎么做。通过设计优质prompt,可以明确任务边界、提供上下文,从而缩小模型的想象空间,提升输出的相关性和准确性。 怎么写出优质提示词明确任务:用动词开头(如“总结”、“对比”等),指定输出角色(如“你是一名律师”)提供上下文:补充背景信息(如“用户是新手妈妈”)和示例结构化格式:要求分点、表格或JSON输出优化策略:使用RTF框架(角色-任务-格式)、思维链(“请逐步分析”,“请给出详细步骤”) 告诉大模型要干嘛,然后补充一些背景资料让它知道,最后规定答案格式,告诉它你要的是什么。 总结Prompt是与大模型高效沟通的密码。通过明确指令、补充细节和规范格式,将模糊需求转化为机器可执行的任务。
