

Transformer
TransformerTransformer是一种基于自注意力机制的神经网络架构,专为处理序列数据(如文本、语音)而设计。其核心由编码器encoder和解码器decoder组成,编码器负责提取输入序列的全局特征,解码器则根据编码结果生成输出。通过位置编码保留序列顺序信息,并通过多头注意力机制并行捕捉不同维度的语义关联。 Transformer就像一个超级大脑,它的设计让它可以同时并行分析一句话里所有词的关系,不需要像传统模型那样逐字读。 Transformer原理Transformer通过一种叫“自注意力”的技术,能够同时关注句子中的所有单词,理解它们之间的关系。 Transformer实践案例GPT系列:基于纯解码器架构,通过海量文本预训练生成连贯内容,如写文章、编程代码。BERT:基于编码器的模型,擅长理解语义,用于搜索引擎优化和问答系统。Sora:结合扩散模型与transformer,生成高质量视频,体现多模态扩展能力。 GPT像作家,输入主题就能编故事;BERT像学霸,擅长考试中的阅读理解;Sora则是导演,用文字描述就能生成视频。它们的共同点是用transformer分...

From Large Language Models to Reasoning Language Models - 计算时代的3个发展阶段
From Large Language Models to Reasoning Language Models - Three Eras in The Age of Computation. Era of model size scaling 模型规模扩展的时代2017 - Transformers “Attention is All you Need” 核心思想与贡献 目标:用纯注意力机制(无需RNN/CNN)解决序列建模问题,实现并行化训练并捕获长距离依赖。 关键创新: **自注意力(Self-Attention)**:动态计算序列中所有位置间的关联权重。 **多头注意力(Multi-Head Attention)**:并行学习不同子空间的注意力模式。 **位置编码(Positional Encoding)**:注入序列顺序信息,替代RNN的时序性。
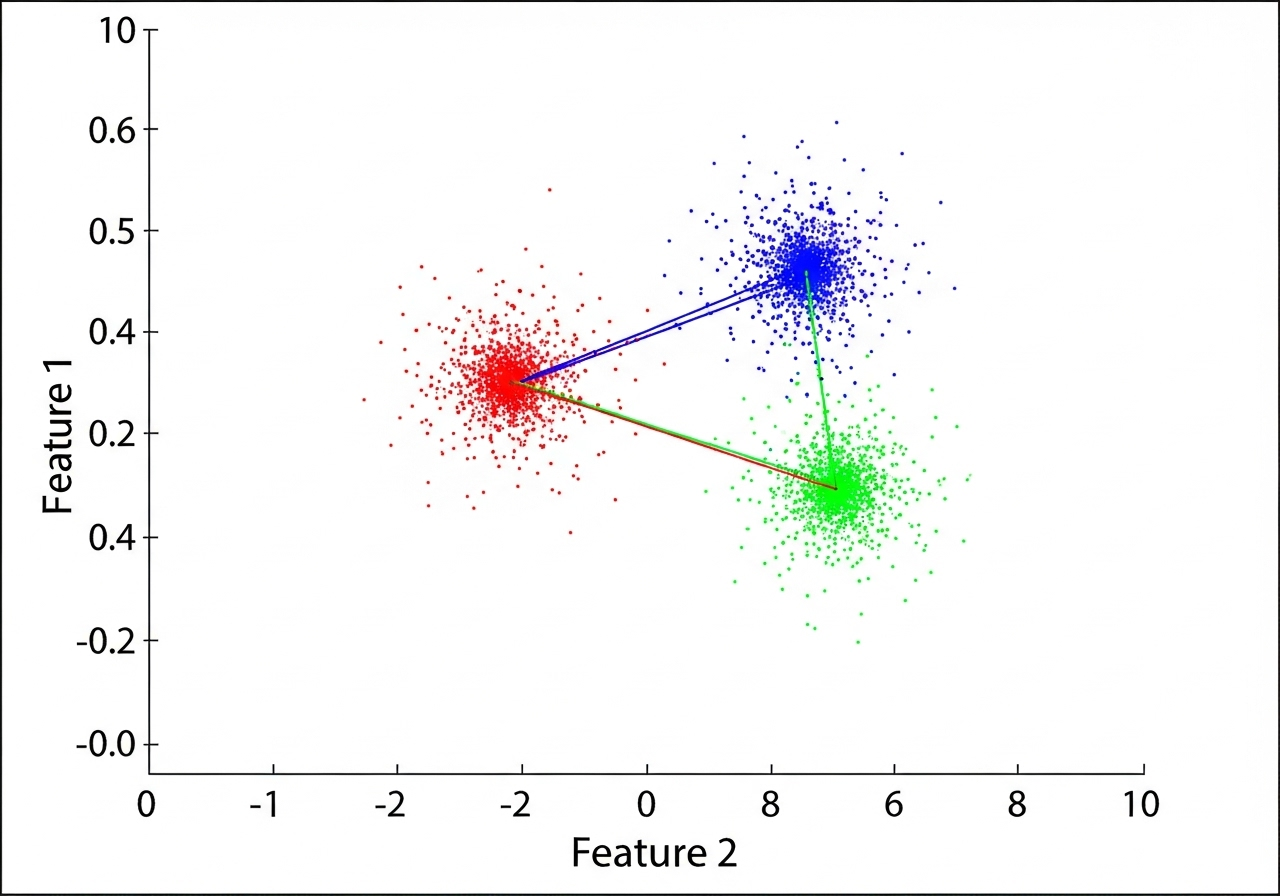
k-means聚类
k-均值聚类kmeans算法是一种常用的聚类算法,属于无监督学习的一种。KMeans算法的基本原理是通过迭代的方式将数据集划分为K个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。 具体步骤初始化:随机选择K个数据点作为初始的聚类中心。分配:计算每个数据点到各个聚类中心的距离,将每个数据点分配到距离最近的聚类中心所在的簇。更新:重新计算每个簇的中心点,通常是取该簇所有数据点的均值。迭代:重复步骤2和3,直到聚类中心不再发生变化或达到预设的迭代次数。 KMeans算法的应用场景和优缺点KMeans算法因其简单高效,被广泛应用于数据挖掘、数据分析、异常检测、模式识别等领域。 优点:简单高效:实现简单,收敛速度快。应用广泛:适用于大规模数据集。可解释性强:结果直观,易于理解。 缺点:对初始值敏感:初始聚类中心的选择会影响最终结果。可能陷入局部最优:算法容易陷入局部最优解而非全局最优解。需要预先指定K值:K值的选取对结果有较大影响,通常需要根据经验或多次试验来确定。 KMeans算法的改进方法K值选择:可以通过肘部法则、轮廓系数等方法来确定最佳的K值。初始化方法:采用...
决策树分类
决策树基本定义决策树是一种利用树形图进行决策的预测模型,表现出对象属性与对象值的一种映射关系,用于分类和回归任务。它是通过训练数据,采用自顶而下的贪婪算法选择最合适的属性作为节点生成的决策树。 属性选择标准 信息增益 (ID3算法) 信息熵 H(D)用来描述系统信息量的不确定度,越混乱,信息熵越高。H(D|A)表示属性A的情况下的熵值。Gain值表示属性A对于系统统一性作出的贡献值,对比所有属性的Gain值,Gain值最高的属性适合做决策树的第一个节点。 条件熵: eg. 风力weak的情况有8次,风力strong的情况6次。week情况下,8次中有6次出去玩,2次不出去玩。strong的情况下,6次中有3次出去玩,3次不出去玩。 根据熵公式,Entroy(weak) = -(0.25* $\log_2 0.25$) - (0.75* $\log_2 0.75$)= 0.8112781244591328Entroy(strong) = -(0.5* $\log_2 0.5$) - (0.5* $\log_2 0.5$)= 1.0 12...

大模型幻觉
大模型幻觉 Model Hallucination大模型幻觉指模型生成的内容存在不符合现实事实(事实性幻觉)或偏离用户指令/上下文(忠实性幻觉)的现象。事实性幻觉:分为“事实不一致”(错误引用信息)和“事实捏造”(无中生有)。忠实性幻觉:包括指令、上下文或逻辑不一致(如答非所问、自相矛盾)。 为什么有幻觉幻觉源于数据缺陷(错误、偏见、过时知识)、训练过程问题(模型架构偏差、对齐目标冲突)和推理阶段的不确定性(随机抽样、解码策略不完美)。 总的来说就是3个方面,1是喂的数据本身不够客观,模型学坏了。2是训练方法没调好,导致模型学歪。3是推理时像抽奖,模型可能随便蒙答案。 怎么解决幻觉检测:用外部知识库验证事实性幻觉(如查百科),通过逻辑分析、指令匹配检测忠实性幻觉。减轻:清洗数据、更新知识;优化训练策略(如强化对齐),推理时增加事实验证步骤(如引用权威来源)。 通俗说就是让模型自己在回答问题前去查资料,检查是否按要求答题以及答题是否符合事实规律,自行再调整。喂给模型更干净、与时俱进的数据,训练时盯紧目标(比如教它诚实),生成答案时候强制引用真实信息。 总结大模型幻觉是“一...

思维链
思维链 Chain of thought思维链CoT是大语言模型通过分步骤推理提升答案准确性的技术。其核心是将复杂问题拆解为多个子任务,生成中间推理结果(如PPI),再整合为最终输出,模仿人类逐步思考的过程。 思维链的原理传统模型直接从输入到输出,而CoT通过算法函数(R函数拆解任务、E函数整合结果)实现分步推理。模型参数规模(如137B)越大,CoT能力越强,但依赖人工设计提示词,且单模态场景有局限。 思维链实践案例Deepseek R1交互:页面展示分步推理过程,如先展示思考过程再生成结果。提示词工程:提问时加“请逐步思考”,准确率显著提升,如文献综述分阶段完成。知识图谱生成:用CoT拆解任务为实体提取、关系分析等步骤。 总结CoT通过分步推理提升大模型答案的准确性和可解释性,但依赖人工设计提示词,且对创新性问题(如数学猜想)泛化能力有限。它是当前提升模型表现的有效工具,但非终极方案。
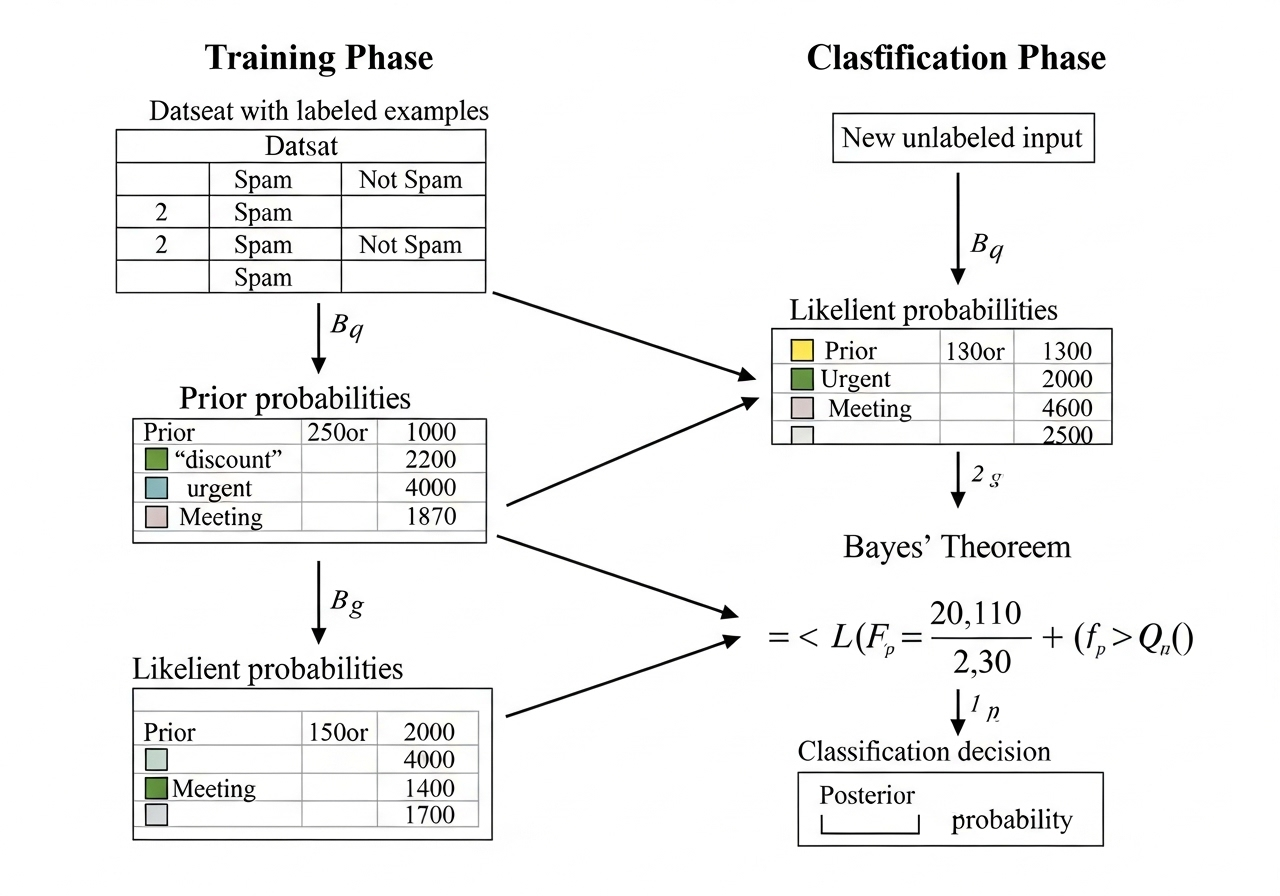
朴素贝叶斯分类
朴素贝叶斯分类贝叶斯分类是一类分类算法的总称,这类算法以贝叶斯定理为基础。而朴素贝叶斯分类是贝叶斯分类中最简单与常见的一种分类方法,它与贝叶斯分类的区别点是加了一个前提假设:所有的条件对结果都是独立发生作用的,即所有的特征之间相互独立。(比如某人是篮球运动员与某人有运动天赋,这两个特征之间是有关联的,不能算作完全独立。而特征有关联性会导致朴素贝叶斯概率误差较大) 贝叶斯公式 先验概率(Prior Probability):P(A)基于过去的经验认知,对某个事件发生概率的初步估计。后验概率(Posterior Probability):P(A|B)表示在特征B已知的情况下,类别A发生的概率。后验概率是基于先验概率和新的证据,通过贝叶斯定理修正后的概率。 在实际情况中,我们利用贝叶斯算法去判断类别时,往往是基于多个特征,极大似然估计MLE是朴素贝叶斯分类模型的简化版,在计算出先验概率和条件概率之后,直接将两者对应乘积。下图中x表示特征,等式表示n个特征情况下是c类别的概率,即条件概率P(B|A)。 当特征数据离散时如何求概率:需要处理数据1.数据离散化:等宽法,等频法,聚类法等。2...
模型参数
模型参数模型参数是神经网络中通过训练调整的权重值,用于将输入数据映射到输出结果。在大模型中,参数规模通常以十亿(B)或万亿(T)为单位,例如GPT-3包含1750亿参数。参数决定了模型对输入数据的处理逻辑,如语言规则、图像特征提取等。参数是模型的经验值,就像人经历越多越聪明,模型参数调整得越准,就能把输入和输出匹配得越好。参数多了,模型还能举一反三,比如从猫咪联想到喵星人。 为什么大模型参数重要参数通过海量数据训练调整,使模型学会从输入到输出的映射规则。训练过程利用反向传播算法,根据预测误差逐步优化参数,最终让模型在翻译、问答等任务中表现更优。参数越多,模型能存储的知识越丰富,例如同时理解语法、语义和上下文。 模型参数怎么用GPT-4通过千亿级参数实现了复杂语言任务(如写代码、创作故事),而谷歌PaLM则在翻译和多轮对话中表现优异。训练时,企业会分阶段优化参数:预训练(用全网数据打基础)、指令微调(教模型按指令执行)、对齐微调(确保输出符合人类价值观)。 总结参数是什么:模型的脑细胞,数量越多越聪明,但算力需求也越大。为什么重要:参数决定模型能学多深、记多细,像超级图书馆的书架越...

模型微调
模型微调大模型微调是指在预训练的大型语言模型(如GPT-3、BERT)基础上,通过特定领域或任务的数据进行二次训练,使模型适应具体需求的技术。预训练模型已具备通用语言理解能力,微调通过调整模型参数,使其在特定任务(如医疗诊断、法律文本分析)中表现更优,同时保留原有知识。就像是让一个通才学霸转行为专科专家。 微调的原理微调的核心是参数调整:预训练模型通过海量数据学习通用规律(如语法、逻辑),参数已初步稳定。微调时,用特定领域数据重新计算损失函数(衡量模型输出与预期差距),反向传播更新部分或全部参数,使模型更贴合新任务。高效微调技术(如LoRA、P-Tuning)通过冻结大部分参数、仅训练少量适配层,降低计算成本。 模型微调实践案例金融情感分析:银行微调模型分析客户评论,识别负面情绪以优化服务,准确率提升30%。医疗诊断助手:某医院微调模型读取CT报告,生成诊断建议,减少医生工作量。中国通信院案例:涵盖工业、能源等领域,如某电力公司微调模型预测设备故障,降低维护成本。 总结大模型微调是让通用AI快速转行的技术。原理上,它基于预训练模型的知识底子,用少量数据调整参数,变成专业工具。实践...
模型蒸馏
模型蒸馏 Knowledge Distillation模型蒸馏是一种将大型模型(教师模型)的知识迁移到小型模型(学生模型)的技术,旨在让小模型在保持性能的同时降低计算资源消耗。其核心是通过对齐两者的输出分布(如概率或特征),使学生模型模仿教师模型的决策逻辑。根据实现方式,分为黑盒蒸馏(仅利用教师模型的输出结果)和白盒蒸馏(额外利用中间层信息)。 蒸馏原理蒸馏的底层逻辑是知识迁移。教师模型的输出(如分类概率)包含隐式知识(软目标),通过损失函数(如KL散度)驱动学生模型的输出与之对齐。同时,学生模型的结构可能被简化或调整,以适配资源限制。例如,白盒蒸馏会利用中间层的特征相似性,而黑盒蒸馏仅依赖最终预测结果。 模型蒸馏实践案例Qwen2.5系列:通过白盒蒸馏实现,利用前向KL散度对齐教师和学生模型的输出,代码开源且效果接近原模型。Deekseek R1:蒸馏过的小模型(8B参数的Deepseek-R1-Distill)在医疗领域微调,性能媲美大模型,且部署成本降低90%。OpenAI实践:通过蒸馏将500B参数模型压缩到100B,训练时间从1个月缩短至1周,大幅降低成本。 总结模型蒸...

