
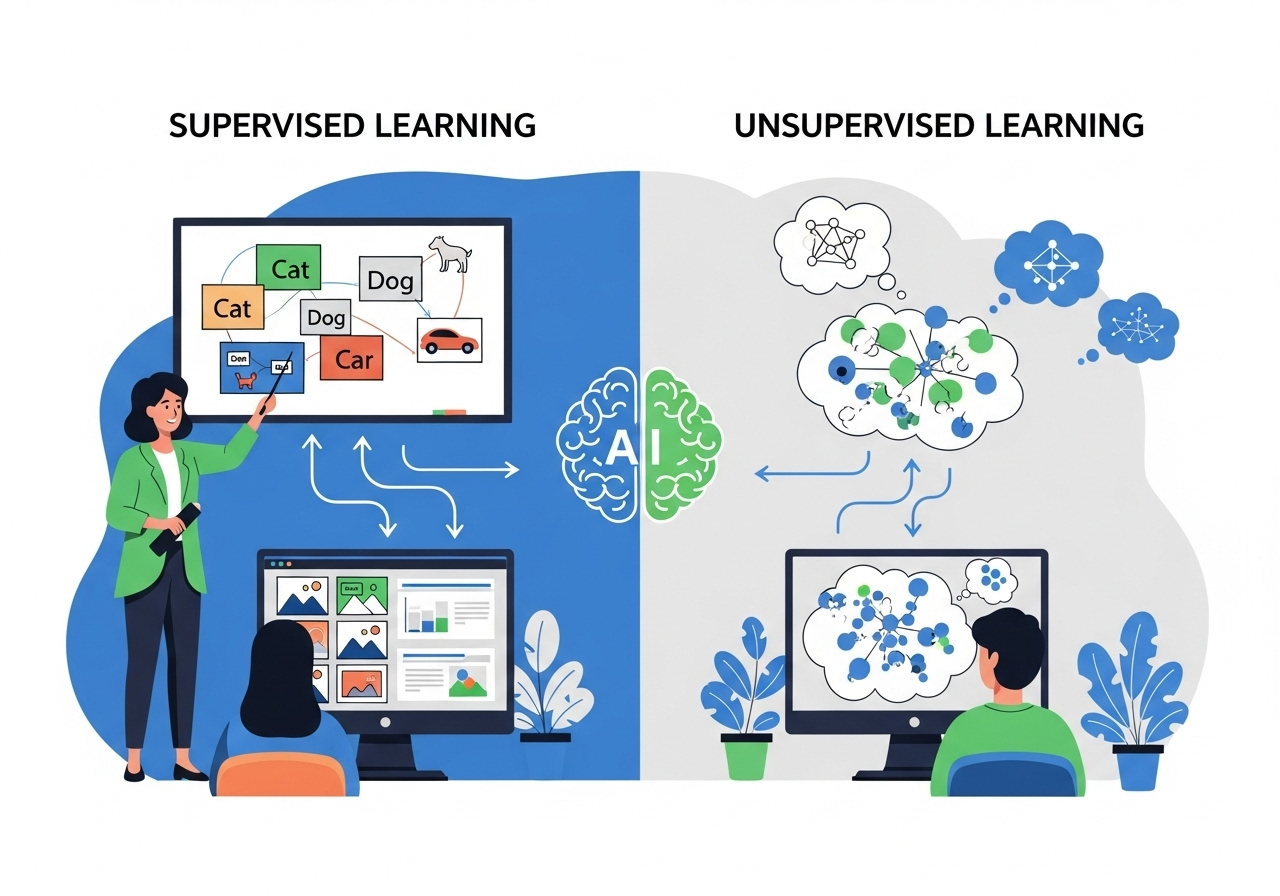
监督学习与无监督学习机制
1.1 监督学习 Supervised Learning训练数据: 有明确标签(数据集的每个样本的多种特征均有标准答案)输出: 有特定结果导向 回归算法regression与分类算法classification均属于监督学习机制,其他函数如支持向量机也属于该机制。 回归通过设计的算法输出连续值continuous value,分类输出离散值 discrete value。 1.2 无监督学习 Unsupervised Learning训练数据:无标签或均为同标签 (无标准答案)输出: 无特定结果导向,需要设计算法自行发现数据的规律。 聚类算法是无监督学习机制中的一种算法,其他函数如奇异值分解也属于该机制。
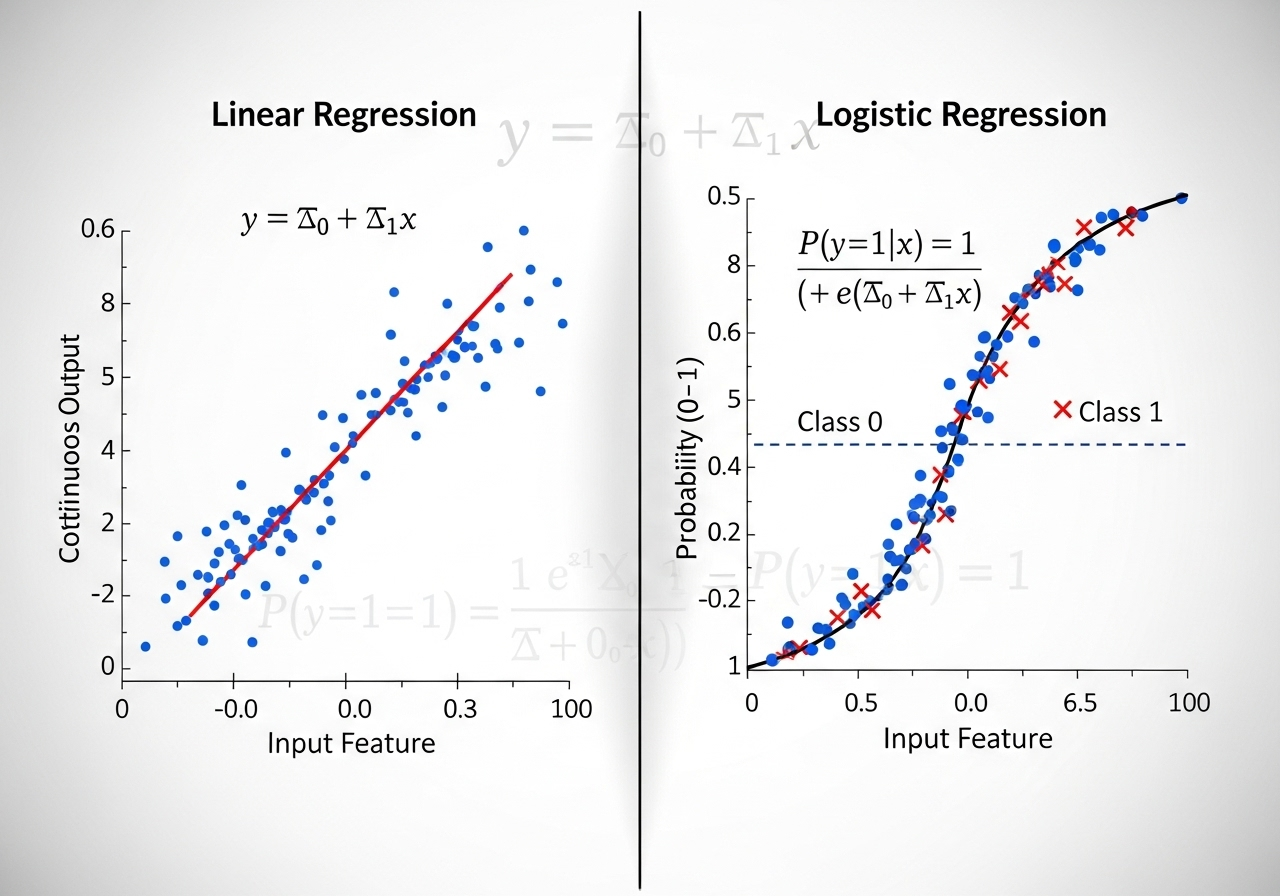
线性回归与逻辑回归
线性回归(Linear Regression)线性回归是一种监督学习算法,用于建立连续型变量(因变量)与一个或多个自变量之间的线性关系模型。核心思想:通过拟合最佳直线(或超平面)最小化预测值与真实值的误差。 数学模型 其中斜率系数代表权重参数。 损失函数损失是一个数值指标,用于描述模型的预测有多大偏差。损失函数用于衡量模型预测与实际标签之间的距离。训练模型的目标是尽可能降低损失,将其降至最低值。 损失类型: 使用不同损失函数训练出的模型,与离群值距离不同。 MSE:模型更接近离群值,但与大多数其他数据点的距离更远。 MAE:模型离离群值较远,但离大多数其他数据点较近。 梯度下降法梯度下降法是一种数学技术,能够以迭代方式找出权重和偏差,从而生成损失最低的模型。梯度下降法会针对用户指定的多次迭代重复以下过程,以找到最佳权重和偏差。 数学上来说主要是求f(x)函数的导数(含多阶导数)找到最佳权重与偏差,导数>0,则导数曲线为凹函数,存在最小值。 逻辑回归(Logistic Regression)逻辑回归(Logistic Regression)是一种用于解决二分类问题的统计模...

预训练
预训练预训练是大模型的核心训练阶段,指利用海量无标注数据(如互联网文本、书籍、网页等)训练模型,使其语言学习的统计规律、语法结构及语义关联,形成通用语言理解能力。这一过程不针对具体任务,而是为模型奠定知识基础,例如GPT-3通过1750亿参数学习通用语言模式。 预训练原理传统AI模型依赖人工标注数据,成本高且泛化性差。预训练通过无监督学习从海量数据中自动提取语言规律,突破数据标注瓶颈。大模型参数规模(千亿至万亿级)使其能捕捉更复杂的语义关联,后续只需少量标注数据微调即可高效适配下游任务。 预训练实践案例GPT系列:通过网页、书籍等数据预训练,再微调实现对话、翻译等任务,如ChatGPT。华为盘古大模型:预训练后仅需行业少量数据精调,即可应用于气象预测、药物研发等领域。IDC报告案例:预训练模型在金融、医疗等场景中,通过“通用知识+小样本微调”降低成本并提升准确率。 总结预训练是大模型的“筑基”阶段,通过海量无标注数据学习通用语言知识;其价值在于降低标注依赖、提升泛化性;实际应用时需结合微调适配具体场景。


